
When you buy something through one of the links on our site, we may earn an affiliate commission.
Knowing how to check your indexed pages on Google is a necessary process when conducting a site audit.
Indexing is Google's way of “allowing” you to appear on search results, or even on Google Discover results. If your pages aren't indexed, you won't appear, and you will not get organic traffic.
However, not all pages will get indexed, and you won’t realize it until you check.
And in this article, I'll show you how and give you some tips on how to get pages indexed more easily.
Contents
How To Check Which Pages Are Indexed By Google?
Below are three ways to know which pages are indexed.
Google Search Console
There are two ways to check which pages are on the Google Index using Google Search Console.
Using the URL Inspection
If you have a few articles on your own site or recently published some articles and want to check if they're indexed, you can use the Google indexed pages checker in Google Search Console as shown below.
All you have to do is enter the page's URL in the search box and click enter. If the page is indexed, you’ll get the following notification.
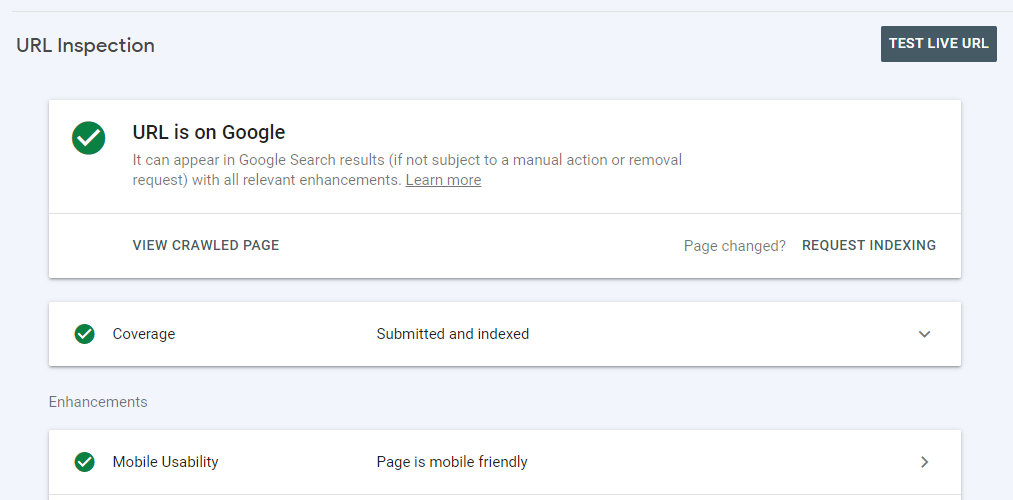
If it’s not indexed, you’ll get the following notification.

As you can see above, the page has been discovered but not indexed. I had just published that article. That's why it was not indexed. You can wait for a few days for Google to automatically index the page or request indexing. But there's no telling how long it will take.
Using the Coverage Feature
On the left-hand side of Google Console, you'll see the Google Index section, which has Coverage, Sitemaps, and Removals. Click on Coverage, and it will show the total number of indexed pages labeled as valid.
Pages that are not indexed are labeled as Excluded. And you’ll also see the pages with errors. Below is an example of how the page looks like;
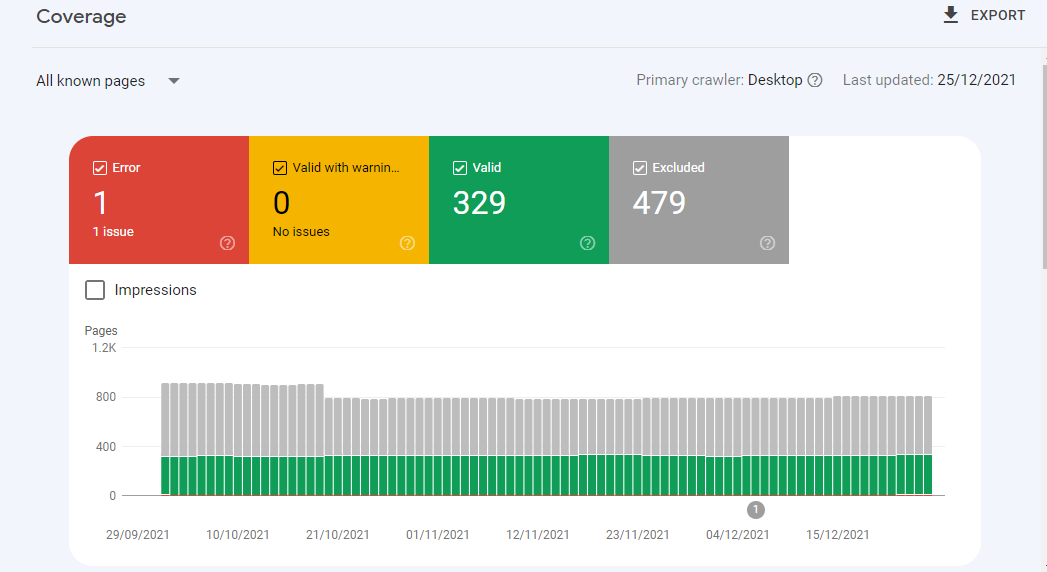
The good thing about the Coverage feature is that it tells you why exactly the pages aren’t indexed or appearing in the search results. For instance, you could get a response saying that the URL is not on Google and a Sitemap: N/A tag on the Coverage, which means the page can be indexed, but it's not on the XML sitemap.
Robot.txt and canonical issues are also shown in the Coverage section, but I’ll discuss what to do about them later in the post.
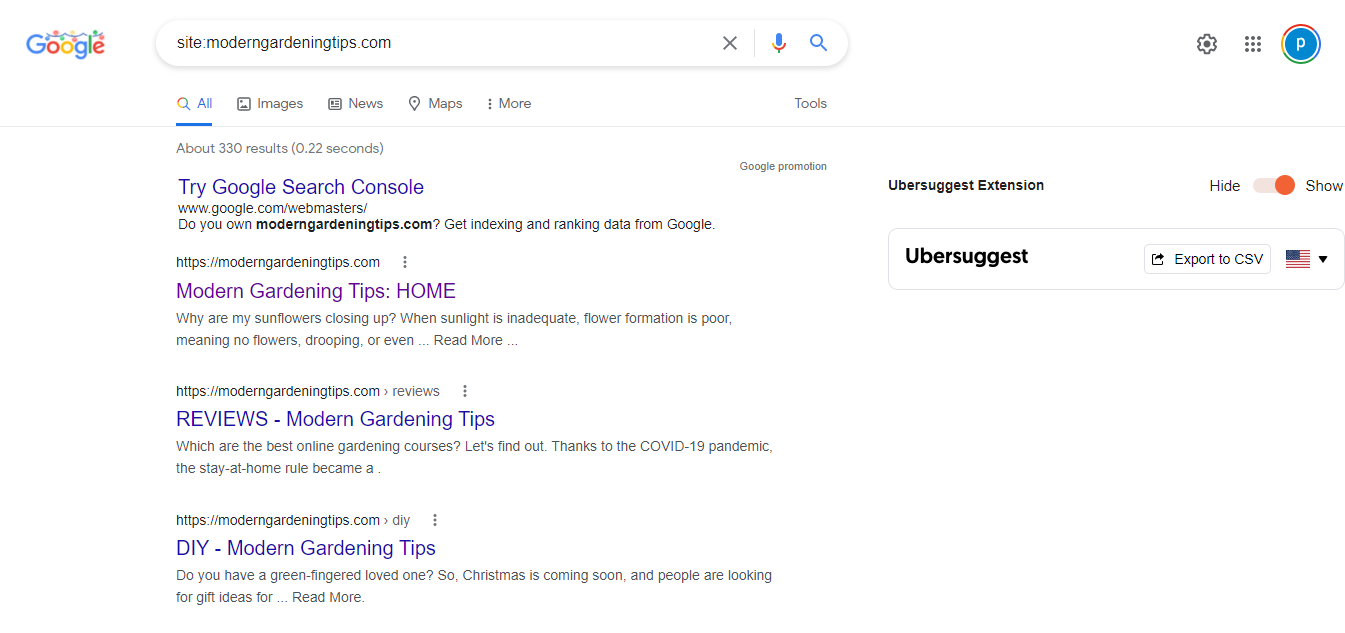
Google Site Query
This is another easy way to check how many pages are indexed. Go to Google Search and enter site:yourdomain.com. For instance, if your website is ilovegardening.com, you will enter sitse:ilovegardening.com, and you'll get a complete list of all the web pages Google indexed from your site. Below is how the page would look like;
You can also narrow the search of your web page by adding more parameters to the command. Below are some of them;
- The Site:mywebsite.com Phrase Of Choice – This command helps find all indexed web pages on your site that have a specific phrase.
- Site:mywebsite.com inurl:Phrase of Choice – Unlike the previous command, this command finds all indexed pages with a specific phrase in the URL.
- Site:mywebsite.com intitle:Phrase – This command will highlight all indexed pages with a specific phrase in the title.
Using Google Indexed Pages Checkers
There are several tools that can help you find the indexed pages more efficiently. These tools include;
- Northcutt – This tool is pretty straightforward. Just enter the URL, and it will tell you all the pages that are indexed on your website. If you know the total pages on your site, you can subtract the indexed pages to find out those that aren’t indexed. Unfortunately, you can’t conduct further analysis to identify which pages aren’t indexed.
- Small SEO Tools – Small SEO Tools is a collection of various tools such as a plagiarism checker, a domain age checker, a grammar checker, and an indexed pages checker. It works great for small sites since it only allows you to check up to 5 pages at a time.
The Crawling Process
When you search a particular query on Google, it takes less than a second to get the results. But a lot happens in the background, which can help a website owner increase their chances of being indexed and appearing on the search results for search users. To understand how it all works, let's first define some of the most common terms used;
- Crawling – This is the process of searching web pages to identify what the content is about and finding more pages through the hyperlinks in the identified pages.
- Index – This is sort of a directory that stores the successfully crawled pages that can appear in the search engine results. The process of saving a web page in an index is called indexing (or Google indexing). And when you get your site indexed, a user types a query on Google, the results are derived from Google's index.
- Web Spider – This is the software responsible for the crawling process. Google’s search engine spiders are known as Googlebot or the Goggle Crawler. And other search engines have their own spiders.
- Crawl Rate – This is how many requests Google bot can make to your site in a second.
- Crawl Demand – This metric measures how much Google bots want to crawl your site. It's determined by your site's popularity since more popular URLs are crawled often. Google also crawls sites often to prevent staleness.
- Crawl Budget – this is the number of pages Google bots can crawl and index within a certain period. If you have too many pages, then search crawlers may not frequent through often.
How It Works
So, when a user enters a query on Google, the Google bot crawls all the pages in the index and uses the links on those pages to find more relevant pages. This process goes on until there are billions of pages. Google then filters these pages by querying them based on relevance to give you the best answer to your question.
Some of the parameters the Googlebot checks include the page rank, the quality of the website, keyword placement, and the number of websites linking to that page.
The result will be all the sites that answer the user's query, the URL to the page, and a short snippet that will help them decide which page they should pick.
They also get several related searches they can try, and you, as the website owner, can use these related searches to find more queries your audience may be interested in.
Google’s crawling process is free and mostly automatic. You are not required to pay anything to get your site crawled or ranked. All you have to do is submit your site’s XML sitemap and make sure your site follows Google’s webmaster guidelines.
As I mentioned earlier, you can also request crawling by requesting indexing. Sure, you might find ads ranking above other content, but even the ads are shown based on relevance and not how much the advertiser paid.
Why Isn’t Google Indexing Your Site
Now that we know how indexing works, let’s find out why your pages may not be indexed.
You’ve Not Submitted Your Sitemap
As mentioned earlier, you must submit your sitemap.xml file for Google to crawl your website. It’s easy to forget about this process, especially with your first website. Or you may have submitted it, but there was an error, and you didn't realize it.
Either way, if Google is not indexing your pages months after you created them, the first thing should be to check and resubmit your site’s Sitemap, which is easy to do, especially for WordPress websites. All you need to do is install the Yoast SEO plugin, which automatically creates the sitemap file.
Just to be sure, go to SEO –General –Features, and make sure the XML Sitemaps is on. Then, type this: https://yourdomain.com/sitemap_index.xml or https://yourdomain.com/sitemap.xml in the Google Search box, and you should see your site's Sitemap. Then, copy this URL and submit it in Google Search Console – Sitemaps. And that's it.
Besides submitting your Sitemap, you also need to ensure all pages are indexed. While Google can easily find all the pages that need to be indexed, you can make it even easier by adding any pages that aren't on the Sitemap.
Crawling Errors
If your pages aren’t being indexed, there could be crawling errors. The Google search crawler often crawls a site to check if the pages have changed or if there is new content published. But this is not always successful due to DNS errors, server errors, URL errors, robot.txt, and many other errors.
You can inspect your website’s crawl health by going to Settings – Crawl Stats, as shown below.

Here, you will get the total number of Crawls within a certain period, the average response time, and the total download size. You can then crosscheck the results on that page with the documentation on this page to find a way to fix them. Fixing these issues will help your organic search traffic.
Robot.txt or Noindex Tags Blocking Some Pages
One of the Crawl errors you may be getting is a Robot.txt file blocking some pages. In most cases, the blocking is done intentionally when you want to instruct Google’s Crawlers not to index a page. But there are instances where it's blocking pages you need to be indexed using the ‘noindex' tag or the following code snippets.
| 1 | User-agent: Googlebot |
| 2 | Disallow: / |
| 1 | User-agent: * |
| 2 | Disallow: / |
Noindex tags also appear in your site's meta tags. Therefore, you need a thorough website audit to make sure the pages you need indexed aren't blocked.
You could get this information from the Coverage section of GSC, using a site audit tool like ahrefs, or manually checking your site's code and the robot.txt file. And removing them isn't that complicated either. Once you find these tags, just manually delete them from the file, and Google will start crawling those pages.
Duplicate Content
If several pages on your site return similar content during crawling, your pages may not be indexed. Some of the reasons you have duplicate pages include;
- Having different versions of a website. For instance, one with a www prefix and one without the prefix. The same applies to HTTP and HTTPS.
- URL variations
- Someone is stealing your content and republishing it on their sites.
You can eliminate duplicate content through the following ways;
- You can delete the duplicate pages if they're easy to find and don't add any value to the main page.
- 301 Redirect – 301 redirects are some of the best SEO practices. If you can’t delete the duplicate pages, redirect them to the main page. This eliminates the duplicate content and improves the relevance of the page, which could potentially improve the rankings.
- Assign a noindex, follow tag – Remember the robot.txt file I mentioned earlier? This is how you manually tell Google's crawlers not to index a page. You can assign the noindex, follow tag to all duplicate content and leave the main page that should be indexed.
- Rel=”canonical” – This feature allows you to tell crawlers that some pages are actual duplicates of the main page, and all page rank power should go to the main page. As such, you will assign the canonical tags Rel=”canonical” on each duplicate page and place the URL to the main page in the tag (find out how to duplicate a page in WordPress here).
- Assign a preferred URL on GSC and block URLs that should not be crawled or indexed.
- Assign a self-referential rel=canonical to the main page to prevent scrapers from stealing your content.
Site Speed
According to this study, a site's loading speed affects how often Googlebot crawls your site. You would want Google to crawl your site often if you constantly update your site's content.
But if a page takes more than 3 seconds to load or doesn't load at all, Googlebot will have a problem indexing it.
Also, if pages are taking too long to load, the Google Crawler may index only a few pages on your site while you need it to crawl and Google index more pages. Site Speed is also known to affect overall rankings, where slow sites rank lower than fast sites. Google even released a core update based on Core Web Vitals in June 2021.
Privacy Settings and .htaccess Files
For those with WordPress sites, altering the Privacy settings can also affect crawling and indexing. To rule out this issue, login into your WordPress admin panel, then go to Settings – Privacy and make sure it’s off.
On the other hand, .htaccess files help with SSI, Mod_Rewrites, Hotlink Protection, Browser Caching, and other functions on the server. But this file may also affect the site’s speed and interfere with the crawling process.
Your Site Was Penalized
If you don’t follow Google Webmaster’s guidelines, your site will lose earnings, traffic, or worse, your pages may be removed from the Google Index. As long as your site follows the Google Webmaster Guidelines, you don’t have to worry about penalties. And you’ll always get a warning before they take such drastic action.
How to Get Your Pages Indexed By Google
I've highlighted several times that you can get your pages indexed quickly by requesting indexing.
This is by submitting the URL to the URL Inspection tool to check its status, and you'll get an option to request indexing. Other methods I’ve mentioned include;
- Checking if the pages are blocked by the robot.txt file or noindex tags
- Eliminating duplicate content
- Fixing crawling errors and loading speeds
- Checking the privacy settings and the .htaccess file.
- Resubmitting the Sitemap
If you did this and your pages are still taking too long to be indexed, below are other tips you can try.
Internal Linking
As mentioned earlier, the crawling process involves following links that are on the page. So, if there are “orphaned” pages or pages that you've not linked to, Google bots may have a hard time finding and indexing these pages.
Conducting a site audit with tools like SEMrush or Ahrefs can help you identify the orphaned content. But if you want to get deeper insights into the whole internal linking process and prevent orphaned content, you should try Link Whisper.
This is a tool designed by Spencer Haws that helps suggest articles to link to based on relevance. It also helps if you start by linking from your best-performing pages – the pages that Google crawls often.
Besides ensuring healthy internal linking, you should also ensure the internal links are not nofollows. Why? Google bots don't crawl nofollow links. You could assign a nofollow tag to outbound links when you don't want to transfer PageRank to another site, but don't do that for internal links.
Publish High-Quality Content and Remove low-Quality Pages
Indexing is not all about technical stuff. You also need to publish content that's valuable and helpful to the reader.
Google bots will first scan the page to determine if it serves the user's intent before scanning the links on that page. If it's a low-quality page, it may not be indexed, and other pages that page links to may not be crawled. As mentioned earlier, Google has a crawl budget.
If you have several low–quality pages on your site, you may deplete the Crawl budget before the high-quality and relevant pages are crawled. But this primarily applies to sites with thousands of pages.
Besides removing low-quality pages, you can also improve the site’s speed, remove duplicate content, fix or remove pages with errors, and enhance internal linking (I’ve discussed how you can do all this in the previous sections).
Other aspects to pay attention to include the headers, tags, and the sites you link to.
Backlinks
Sites that link to your site also matter. Backlinks show Google that your site has more value, and Googlebot will likely crawl them more often than those without.
Sharing your content on social media is an excellent way to get your business out there, improve rankings, generate traffic and leads.
But what you might not know is sharing your content also creates social signals, which can help trigger Google Crawlers to crawl and index your pages. Some of the places you can publish your content to speed up indexing include;
- Medium
- Quora
- Digg
- SlideShare
How to Check Which Pages Are Indexed By Google
And there you have it. If your traffic isn't growing as you'd expect, or you've experienced a drop, chances are Google crawlers are having trouble crawling and indexing your pages.
I've detailed all the different ways you can check which pages are indexed by Google, identify indexing issues, and fix them. This will help you rank higher in Google SERPs to attract more search users.
Remember, not appearing in Google Search results doesn’t mean you’re not indexed. You may be indexed but are ranking very low since your site lacks authority.
And for further reading check out our list of other clever ways for how to get more pages indexed by Google.
Related Posts






Want to learn step-by-step how I built my Niche Site Empire up to a full-time income?
Yes! I Love to Learn
Learn How I Built My Niche Site Empire to a Full-time Income
- How to Pick the Right Keywords at the START, and avoid the losers
- How to Scale and Outsource 90% of the Work, Allowing Your Empire to GROW Without You
- How to Build a Site That Gets REAL TRAFFIC FROM GOOGLE (every. single. day.)
- Subscribe to the Niche Pursuits Newsletter delivered with value 3X per week
My top recommendations











